
TL;DR
Gas Town is a powerful multi-agent workspace manager, but running a swarm of parallel agents against a cloud API burns through credits at an alarming rate. I picked up an NVIDIA DGX Spark, self-hosted the Qwen3-Coder-Next-FP8 model using vLLM, and swapped Claude Code out for OpenCode to serve as Gas Town’s local coding agent. The result: minimal per-token costs and a foundation I can tune and optimize over time.
Why Go Local?
If you’ve spent any time with Gas Town, you know it’s not shy about token consumption. Steve Yegge designed it to orchestrate swarms of coding agents in parallel, with the Mayor coordinating Polecats, the Refinery managing merge queues, and several other specialized roles all chattering away simultaneously to keep things moving. This is incredibly powerful, but it comes at a cost. Early adopters reported burning through $100+ per hour in tokens when running at full tilt.
I had been using Claude Code as Gas Town’s primary agent, and the quality was excellent. However, as I started scaling up to more concurrent agents and longer sessions, the bill started to look less like a utility cost and more like a car payment. Even with a Claude Code Max 5x subscription, I was continually hitting the daily session usage rate limit (multiple times per day). Three things pushed me to explore a local inference setup:
- Cost: Running a dozen agents in parallel for hours on end adds up quickly, even with smaller models
- Control: I wanted the ability to experiment with different models, quantization levels, context window sizes, inference parameters and other advanced optimization techniques without being locked into a single provider
- Privacy: Some of the projects I run through Gas Town may involve sensitive data. Keeping inference (almost) entirely on my local network eliminates that concern
The Hardware: NVIDIA DGX Spark

The DGX Spark is built around NVIDIA’s GB10 Grace Blackwell Superchip. The specs that matter most for local inference are:
- 128 GB unified memory shared between the CPU and GPU: This is a shared memory architecture, so your model weights, KV cache, and intermediate tensors don’t need to be copied between CPU and GPU. That reduces latency and overhead—especially important for large context windows and multi-step agent workflows where data is constantly moving.
- Up to 1 petaFLOP of FP4 AI performance: FP4 support means you can run aggressively quantized models, trading a bit of precision for major gains in throughput and memory efficiency—critical for fitting larger models or running multiple models concurrently. 1 petaFLOP is the theoretical peak throughput when running FP4 workloads. In practice, it translates to higher token/sec and better concurrency for inference—especially when combined with optimizations like prefix caching or speculative decoding.
- You can link two Sparks together if you outgrow a single unit: This gives you a path to horizontal scaling. You can connect multiple units with high-bandwidth, low-latency networking, enabling distributed inference or model sharding. It’s the bridge from “single-node tinkering” to something closer to a mini inference cluster.
The 128 GB of unified memory is the real selling point here, as it significantly increases your options for self-hosting powerful, open weight models for local inference. You also have the flexibility to host multiple models simultaneously.
The Model: Qwen3-Coder-Next-FP8
Qwen3-Coder-Next is an 80B parameter mixture-of-experts model with only 3B active parameters at inference time, and the FP8-quantized checkpoint fits comfortably within roughly 80 GB. That leaves a healthy amount of headroom for KV cache, vLLM overhead, and the operating system itself. This model is purpose-built for coding agents and local development. A few things make it a particularly good fit for this use case:
- 3B active parameters (80B total) thanks to the MoE architecture, achieving performance comparable to models with 10 to 20x more active parameters
- 256K context length, which is critical for agentic workflows where tool definitions, system prompts, and multi-turn conversations can eat through context quickly
- Strong tool calling support, meaning it can handle the function calls that OpenCode (and by extension, Gas Town) relies on
- FP8 quantization with a block size of 128, balancing quality and memory efficiency
The FP8 variant is the sweet spot for the DGX Spark. It’s small enough to run comfortably with generous KV cache allocation, but large enough to produce quality output for complex coding tasks.
Setting Up the Inference Server with vLLM (Docker)
vLLM is an inference engine that maximizes throughput and minimizes memory waste. It exposes an OpenAI-compatible API, which is exactly what OpenCode needs to connect. NVIDIA provides a pre-built vLLM Docker image optimized for the DGX Spark’s ARM64 Blackwell architecture, so we don’t need to build anything from source.
Prerequisites
Ensure you have the following:
- DGX Spark with the latest system software
- Docker installed
- Access to the NVIDIA container registry (
nvcr.io)
Serving the Model
Before serving the model, we need to download it. Using the Hugging Face CLI provides the most trivial and straightforward way to retrieve open weights.
1
hf download 'Qwen/Qwen3-Coder-Next-FP8'
NVIDIA publishes optimized vLLM images to their container registry. We can pull the image and serve the model in a single command:
1
2
3
4
5
6
7
8
9
10
11
12
docker run -it \
--gpus all \
-p 8000:8000 \
-v /home/user/dgx-spark/cache/huggingface:/root/.cache/huggingface \
nvcr.io/nvidia/vllm:26.02-py3 \
vllm serve Qwen/Qwen3-Coder-Next-FP8 \
--served-model-name qwen3-coder-next \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--gpu-memory-utilization 0.85 \
--enable-prefix-caching \
--attention-backend flashinfer
A few notes on the flags:
--gpus alland-p 8000:8000: Gives the container full GPU access and exposes the inference API on port 8000--served-model-name qwen3-coder-next: Aliases the model with a shorter name, which simplifies the OpenCode and Gas Town configuration downstream--enable-auto-tool-choiceand--tool-call-parser qwen3_coder: Required for OpenCode’s tool calling to work properly--gpu-memory-utilization 0.85: Allocates 85% of available GPU memory to vLLM, leaving headroom for the OS and other processes. You can push this higher if you’re not running anything else on the Spark. Conversely, you can also lower this allocation to serve additional, smaller models on the same Spark--enable-prefix-caching: Caches common prompt prefixes across requests, which is a significant optimization when multiple Gas Town agents share similar system prompts and tool definitions--attention-backend flashinfer: Uses the FlashInfer attention backend for improved throughput on Blackwell GPUs
If the container exits with an out-of-memory error, try lowering
--gpu-memory-utilization(e.g., 0.75) or adding--max-model-len 32768to cap the context window (although this may clash with Gas Town’s context window requirements). Check the logs withdocker logs <container_id>.
Once the server is ready, verify it’s healthy:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
curl -s http://SPARK_IP:8000/v1/models | jq '.'
{
"object": "list",
"data": [
{
"id": "qwen3-coder-next",
"object": "model",
"created": 1774671204,
"owned_by": "vllm",
"root": "Qwen/Qwen3-Coder-Next-FP8",
"parent": null,
"max_model_len": 262144,
"permission": [
{
"id": "modelperm-12345",
"object": "model_permission",
"created": 1774671204,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
}
]
}
Note the model ID in the response reflects the
--served-model-namevalue, not the Hugging Face repository name. This is the ID you’ll reference in your OpenCode and Gas Town configurations.
Configuring OpenCode
OpenCode is a Go-based AI coding agent built for the terminal. Unlike editor-embedded assistants, it lives in your shell and works with any language, any editor, and any environment. More importantly, it supports any OpenAI-compatible API endpoint, which means pointing it at our local vLLM server is straightforward and economical!
Installation
1
curl -fsSL https://opencode.ai/install | bash
Configuration
Create or edit ~/.config/opencode/opencode.json:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"vllm": {
"npm": "@ai-sdk/openai-compatible",
"name": "vLLM (local - DGX)",
"options": {
"baseURL": "http://SPARK_IP:8000/v1"
},
"models": {
"qwen3-coder-next": {
"name": "qwen3-coder-next"
}
}
},
},
"model": "vllm/qwen3-coder-next"
}
Fire up OpenCode, confirm it connects and verify the local model is being used:
1
opencode
If tool calls aren’t working, the most common culprit is insufficient context
length. OpenCode’s system prompt and tool definitions alone consume a
significant number of tokens. Make sure the model’s vLLM instance has an adequate
--max-model-len configured.
Wiring It Into Gas Town
With OpenCode successfully talking to our local models, the final step is
configuring Gas Town’s config.json to use OpenCode as the agent for
its various roles. Gas Town allows you to define custom agents and assign them
to specific roles, giving you granular control over which model handles what.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
{
"type": "town-settings",
"version": 1,
"default_agent": "claude",
"role_agents": {
"polecat": "opencode-qwen3",
"witness": "opencode-qwen3",
"refinery": "opencode-qwen3",
"deacon": "opencode-qwen3"
},
"agents": {
"opencode-qwen3": {
"command": "opencode",
"args": [
"--model", "vllm/qwen3-coder-next"
]
}
}
}
A few things to note about this configuration:
default_agentremainsclaude: The Mayor still runs on Claude for now. As the primary orchestrator, the Mayor’s decision quality has a cascading effect on every downstream task. I’m not ready to hand that off to a local model yet- All worker roles use
opencode-qwen3: Polecats (the ephemeral workers that write code), the Witness (health monitor), the Refinery (merge queue), and the Deacon (patrol loops) all run against Qwen3-Coder-Next via the local vLLM instance. These roles account for the vast majority of token usage
At this point, Gas Town’s Mayor dispatches tasks to Polecats running OpenCode against the local model. The entire inference pipeline for worker agents stays on the DGX Spark, and the only cloud API traffic comes from the Mayor itself.
You can run a sanity check by running gt mayor attach in your Gas Town
directory, instruct the Mayor to define work (create beads) and delegate it
to Polecats (sling beads), and attaching to one of the Polecat tmux sessions.
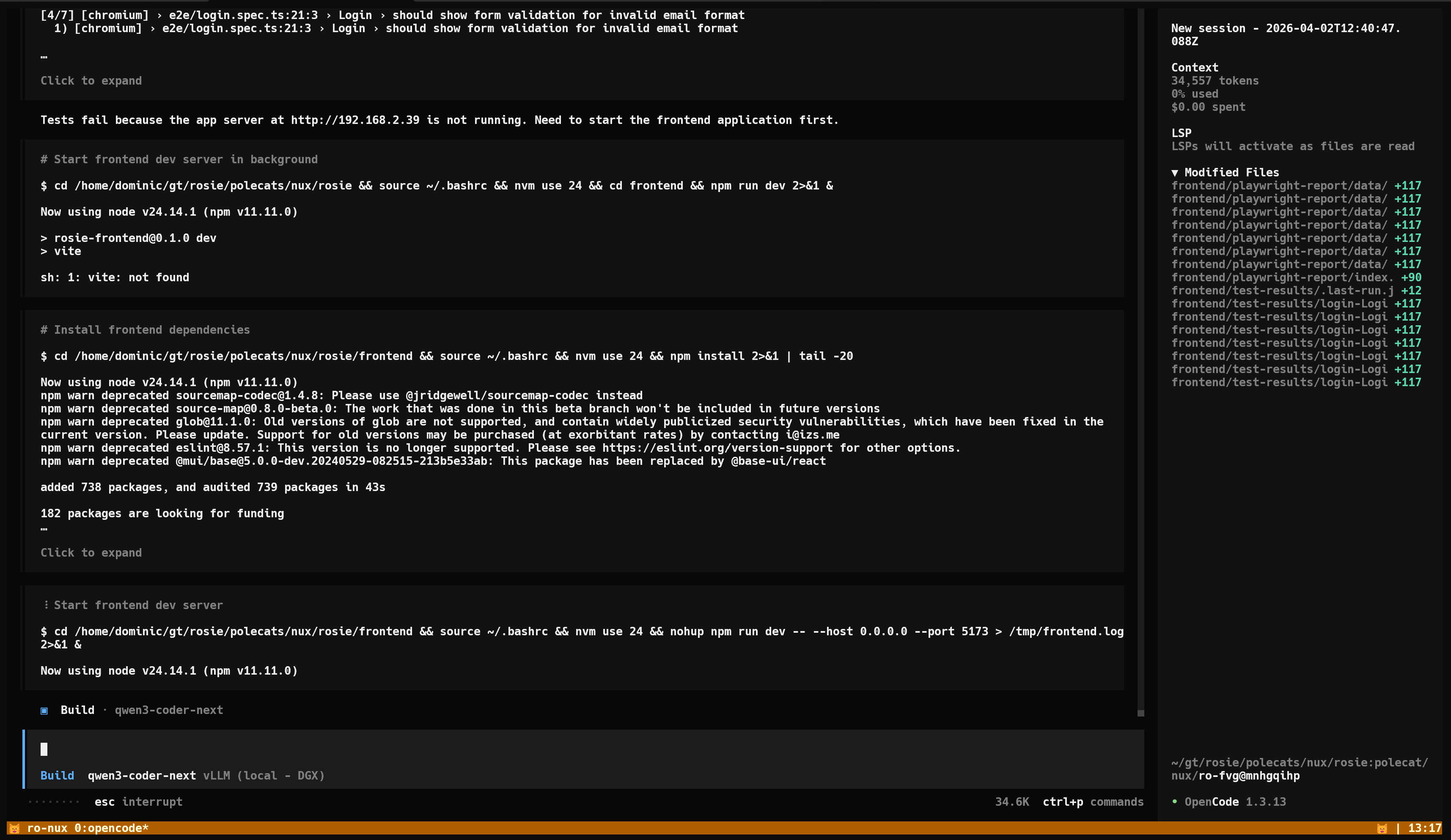
Early Observations
I’ve been running this setup for a few weeks now, and a few things stand out:
Token throughput is the bottleneck, not quality. Qwen3-Coder-Next-FP8 handles the vast majority of Gas Town’s tasks competently. Where I notice a difference compared to Claude is in throughput. When all Polecats are active simultaneously, the local inference setup latency increases. For tasks that aren’t time-sensitive, this is perfectly acceptable. For rapid iteration loops, it can feel slower.
Cost savings are immediate and dramatic. My previous Claude Code usage for Gas Town was rate limited multiple times per day before incurring additional usage token costs. Since deploying this setup, I haven’t once hit the same rate limit, let alone additional usage costs. If this pattern continues, the Spark will pay for itself in a few months.
The optimization surface is wide open. This is what excites me most. With full control over the inference stack, I can experiment with:
- Speculative decoding to improve throughput
- Different quantization levels (FP4 could free up even more memory for larger context windows)
- Request batching and scheduling optimizations in vLLM
- Swapping in newer or more specialized models as they’re released
- Linking a second DGX Spark for tensor parallel inference
What’s Next
This setup is a starting point, not the endgame. I’m planning to explore a few areas in the coming weeks:
- Multi-agent development: Quick iteration and evaluation of specialized AI agents, with a particular fo us on threat detection engineering and incident response automation
- Post-training: Learn Reinforcement Leaning by doing. Post-train small language models to specialize in targeted tasks and sub-domains within threat detection and incident response
- Intelligent routing: Using a local model for routine tasks (linting, simple refactors, boilerplate generation) while routing complex architectural work to a cloud API
- Multi-model routing: The Qwen/Qwen2.5-3B-Instruct-AWQ model is already configured and ready to go. The next step is assigning it to the Witness and Deacon roles to free up Qwen3-Coder-Next capacity for the Polecats
If you’re running Gas Town and the API bill is giving you pause, I’d encourage you to look into a local inference setup. The DGX Spark is not the only option here; any machine with sufficient GPU memory can serve as the foundation. The important part is that the entire stack, from vLLM to OpenCode to Gas Town, is built around OpenAI-compatible APIs, making the components interchangeable.
As always, feel free to reach out on Twitter or LinkedIn with any questions and feedback you may have!